
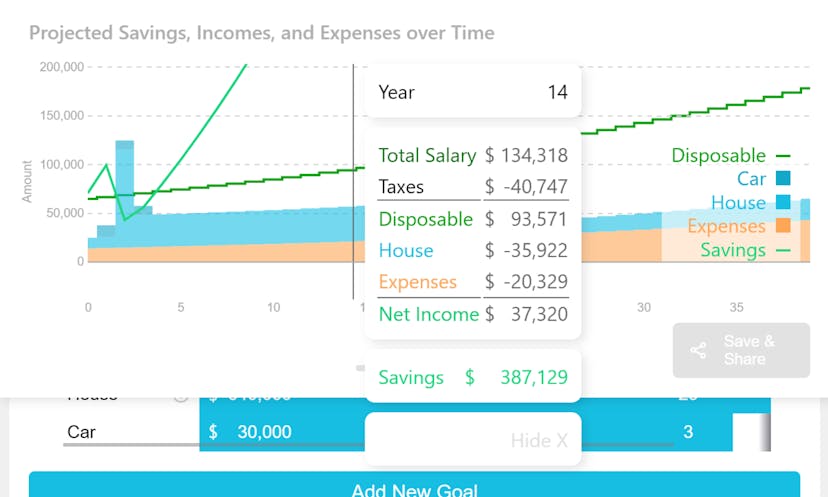

Empowers financial freedom by projecting big-ticket decisions, incomes, and expenses with taxes automatically included.
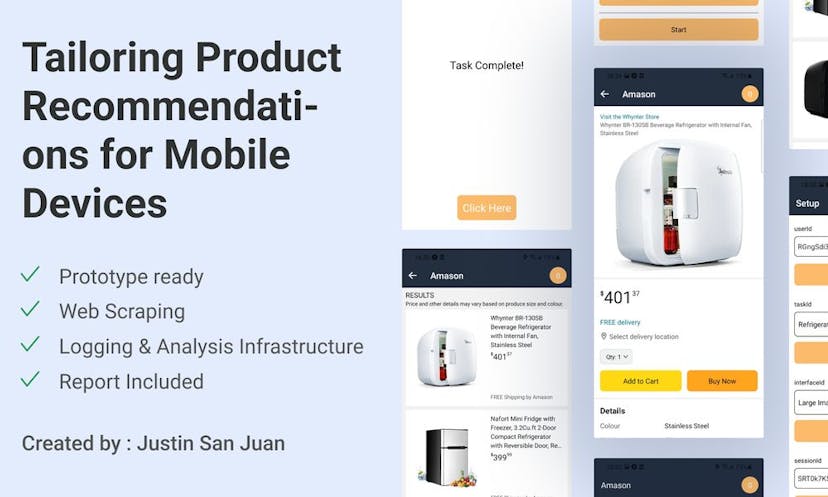
Tailoring Product Recommendations for Mobile Devices. A research project in user interface design. Includes a React Native prototype app, web scraping code, logging & analysis AWS infrastructure, and report.
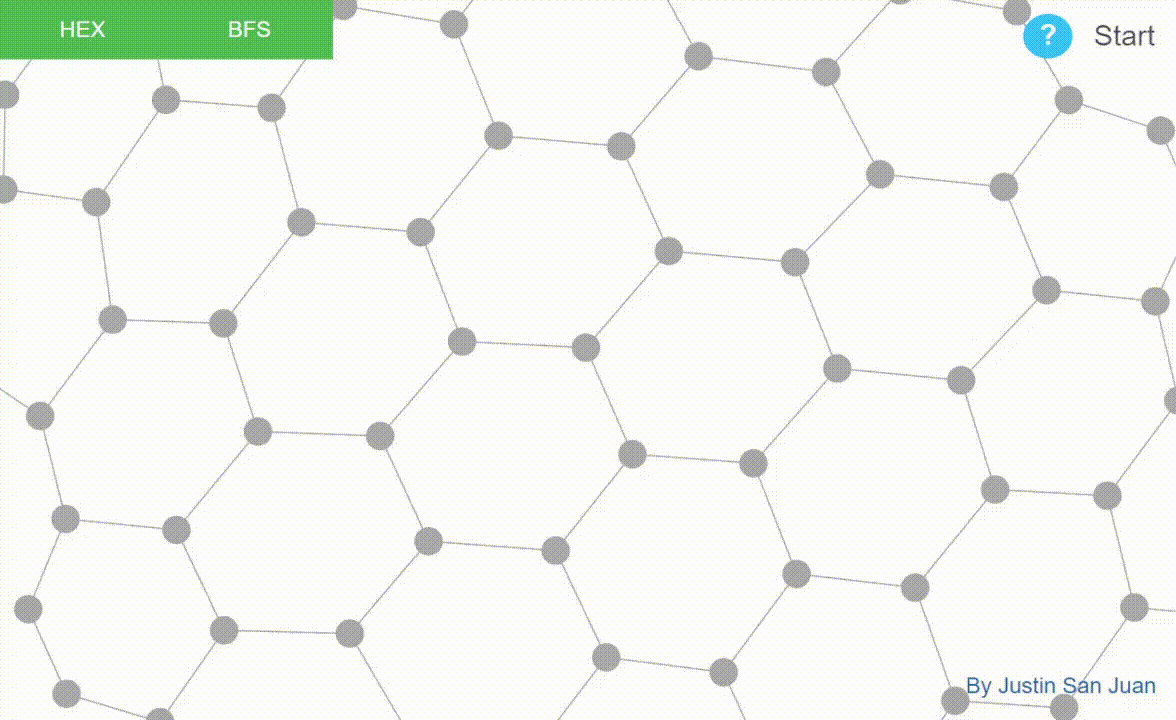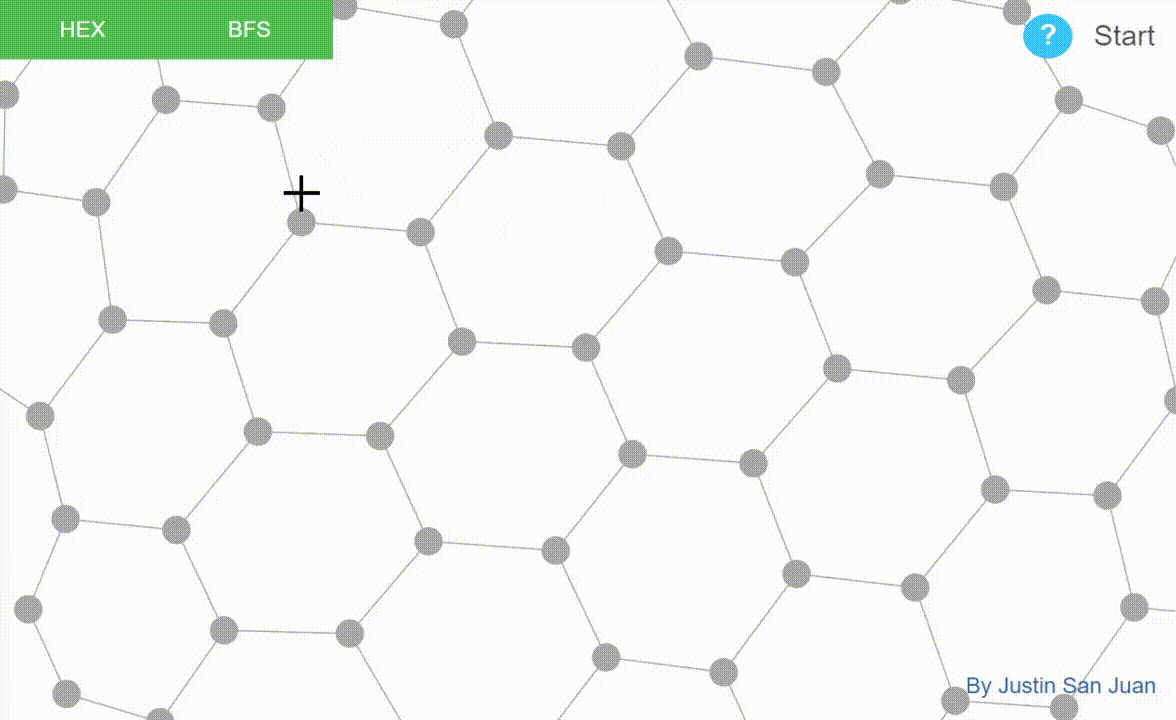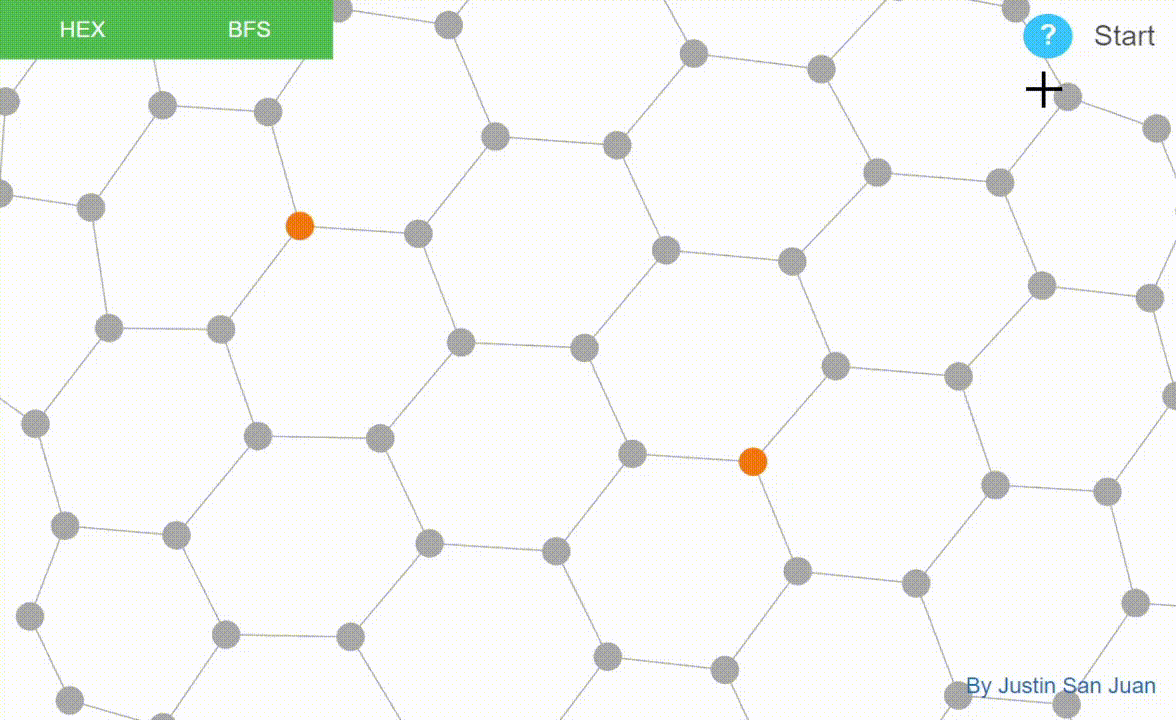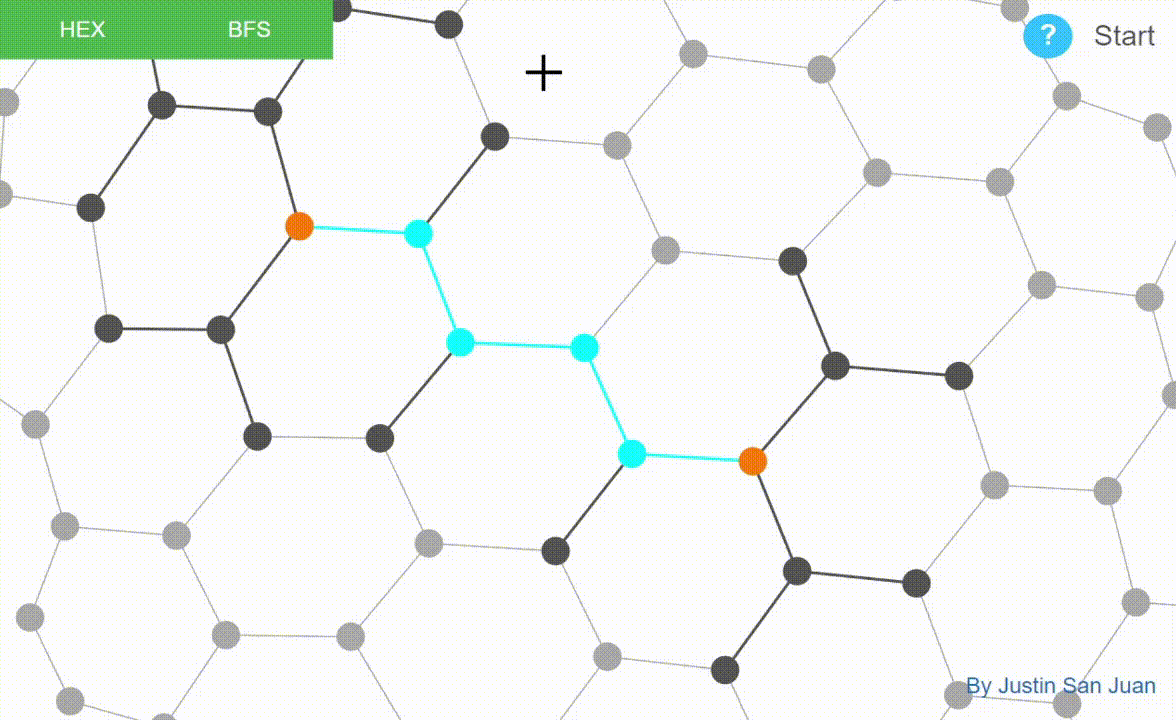
Graph algorithms implemented and visualized in D3.

Reading Made Easier. Made for enhancing focus and empowering readership among people.
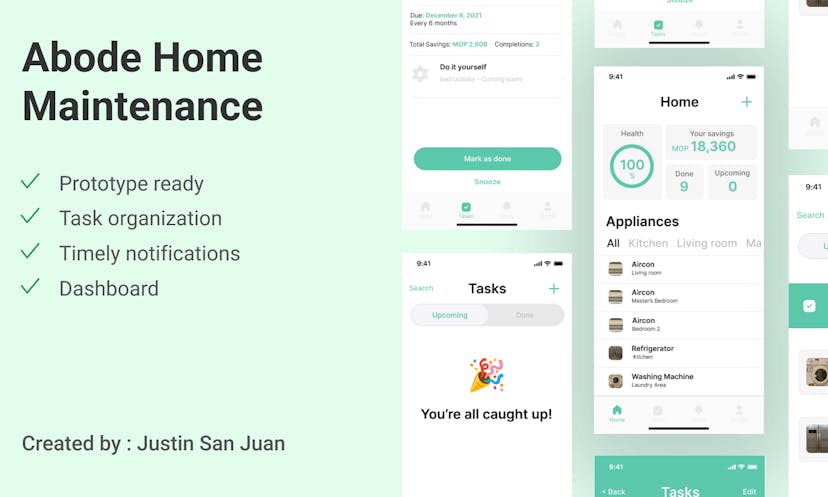
A frictionless app to schedule home appliance maintenance. Users can set up their home appliances, pets, vehicles, and get timely notifications on when to maintain it.

An app for university students to find professional activities that match their interest.

A mobile social party game. A fun activity to test your lyrics knowledge!

An interactive responsive company website with custom display components on WordPress.
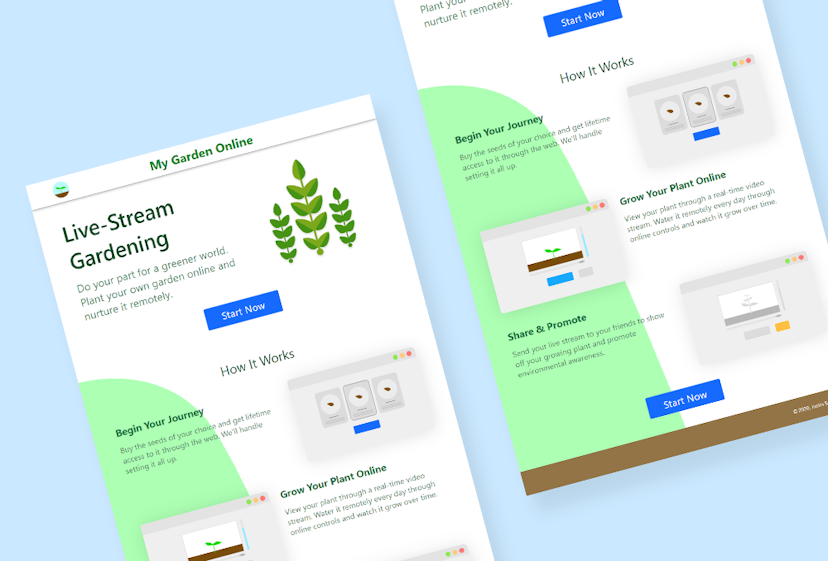
Live-stream every plant you buy. Take care of your garden with water and fertilizer from the comfort of your home online.
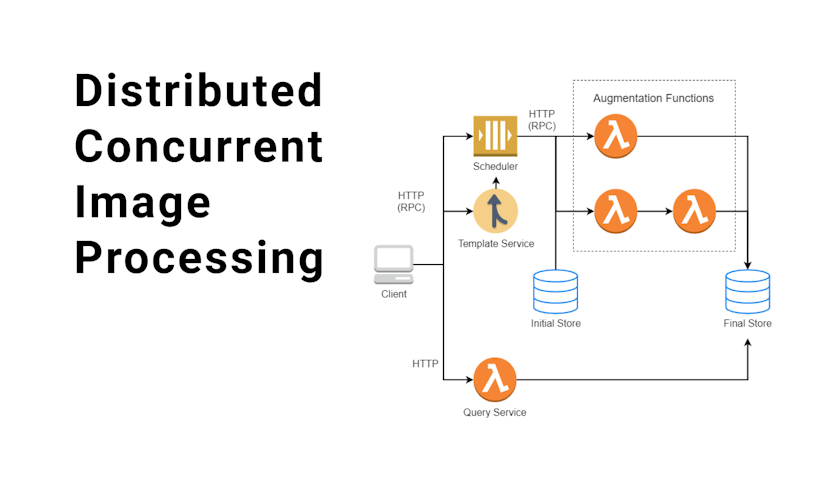
Scalable Kubernetes & Docker distributed system for mass-processing of image payloads. Developed to process 10,000+ images for testing scheduling algorithms.
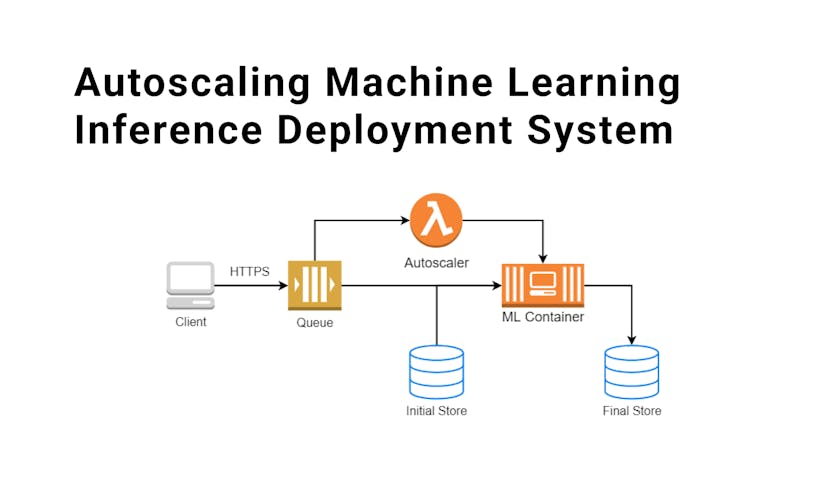
Autoscaling machine learning inference deployment system serving over 100,000 customers.
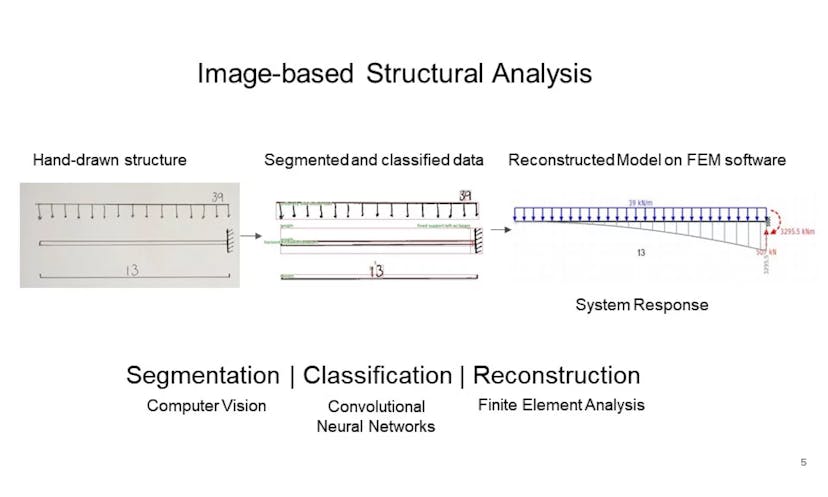
Novel Tensorflow architecture developed to recognize components and numbers in hand-drawn Civil Engineering sketches.

Commercial WhatsApp Business API Solution with over 10,000 messages sent a day per client.

Production-environment trading algorithm with pipelined optimization for Probabilistic Sharpe Ratio build on QuantConnect.
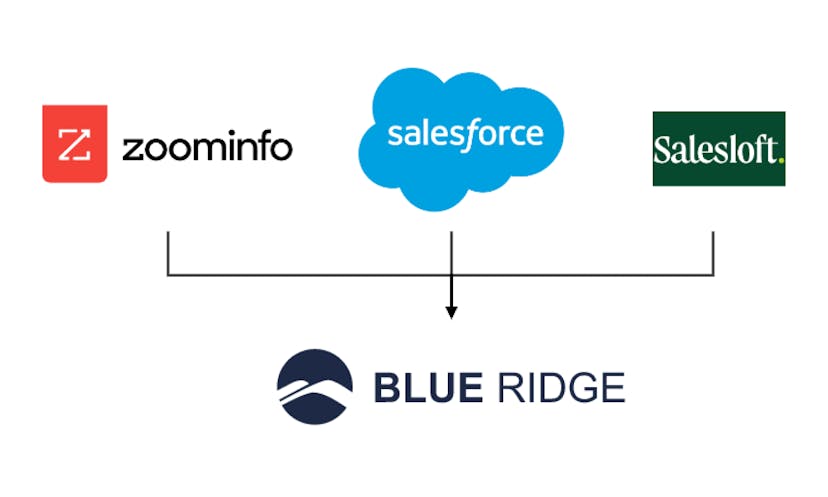
Client-based automation for parsing, filtering, and establishing high-value leads for Blue Ridge Global.
A lightweight, extendable, fast performing, highly customizeable, production ready React Component that renders an animated set of popups.
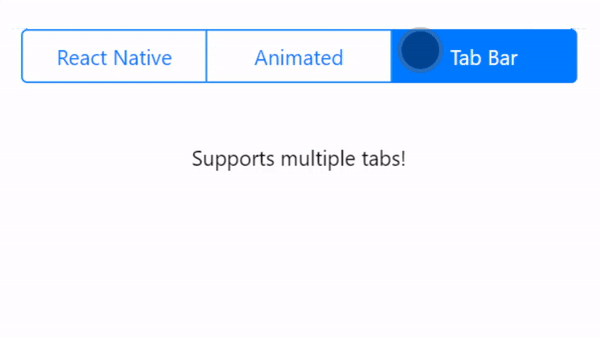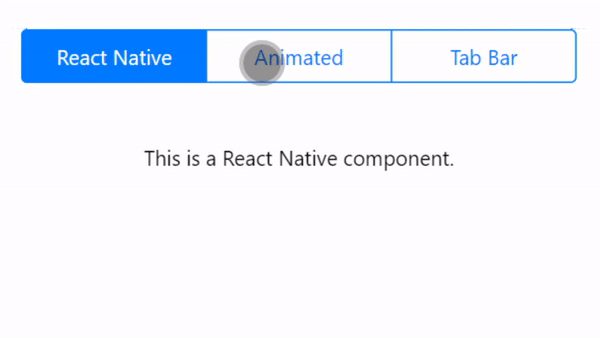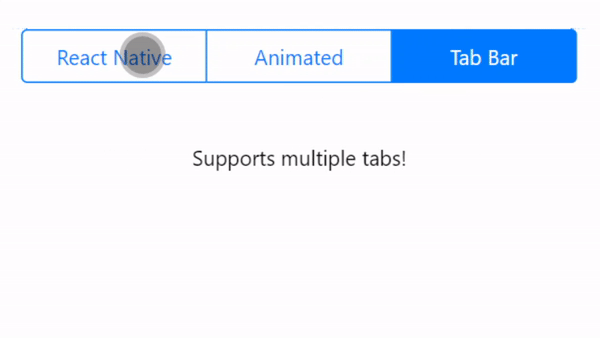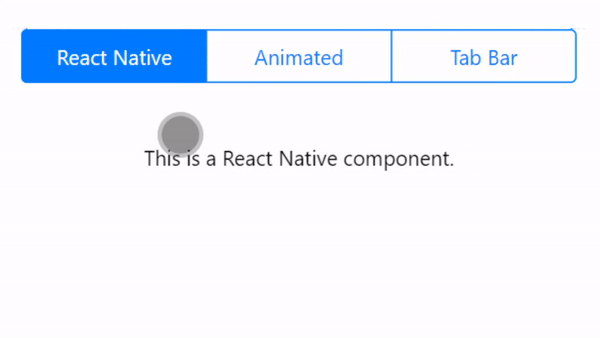
Animated Sliding Tab Bar for React Native. This project supports 2+ tabs with an animated bar to switch between the tabs. This project uses Expo. Inspired by Aditya Signh's original version.
Other open source contributions I have made.


2023 · The rapid growth of Deep Learning (DL) has led to increasing demand for DL-as-a-Service. In this paradigm, DL inferences are served on-demand through a serverless cloud provider, which manages the scaling of hardware resources to satisfy dynamic workloads. This is enticing to businesses due to lower infrastructure management costs compared to dedicated on-site hosting. However, current serverless systems suffer from long cold starts where requests are queued until a server can be initialized with the DL model, which is especially problematic due to large DL model sizes. In addition, low-latency demands such as in real-time fraud detection and algorithmic trading cause long inferences in CPU-only systems to violate deadlines. To tackle this, current systems rely on over-provisioning expensive GPU resources to meet low-latency requirements, thus increasing the total cost of ownership for cloud service providers. In this work, we characterize the cold start problem in GPU-accelerated serverless systems. We then design and evaluate novel solutions based on two main techniques. Namely, we propose remote memory pooling and hierarchical sourcing with locality-aware autoscaling where we exploit underutilized memory and network resources to store and prioritize sourcing the DL model from existing host machines over remote host memory then cloud storage. We demonstrate through simulations that these techniques can perform up to 19.3× and 1.4× speedup in 99th percentile and median end-to-end latencies respectively compared to a baseline. Such speedups enable serverless systems to meet low-latency requirements despite dynamic workloads.

2022 · The emergence of the Function-as-a-Service (FaaS) paradigm enables software developers to focus on business logic all the while entrusting the service provider in a serverless environment to elastically scale up during a burst of requests or scale down when request rates are low. One of the key enablers of FaaS is the widespread adoption of containerization technology such as Docker, which packages software into images that can be loaded and executed in any other computer running the Docker engine. An encumbering limitation of FaaS is significant overhead when downloading these images to newly instantiated workers from a centralized image repository. Large bursts of requests cause new workers to be instantiated and lead to so-called "cold-start" latencies. Recent works have investigated distributed image registries in the flavor of downloading images from existing workers and the scheduling of functions with knowledge of the server resource availability and function request information separately. However, the scheduling of functions in servers distant from existing images can lead to sub-optimal function completion times, especially in the context of a bursty workload. FaaSFabric addresses these issues by incorporating the information of image locations into the scheduling decisions. In this paper, we present fine-grained overhead breakdowns of workload traces, a Mixed Integer Linear Program (MILP) formulation of incorporating distributed image registry information in request allocation decisions, a justification of the potential of Deep Reinforcement Learning (DRL), and a proposed DRL formulation. We also demonstrate that in a simple workload, image pulling can take up to 80% of the total function completion time on average, which shows the potential for a distributed image registry-aware scheduler to outperform baseline and state-of-the-art schedulers.

2022 · Since the beginning of the COVID-19 pandemic, online shopping has grown at a rate not seen before. Because of this, it is pertinent to display product recommendations in a way that makes it easy for users to understand what they are looking at and find what they need. Currently, there exists a lack of research on how to tailor the display of these recommendations to different devices. This is especially important for mobile devices where there is significantly less space to display all of the necessary information. In this paper, we explore two factors that influence a user’s product selection decision process on mobile devices, mainly the size of the picture and amount of explanation for each product, and perform a user study to quantify the amount of influence these factors have.

2021 · Decentralized applications built using smart contracts are skyrocketing. These applications take advantage of blockchain’s availability and security guarantees. However, blockchains have failed to cope with the increase in adoption because of inherent limited scalability and poor throughput. This prevents mainstream adoption of application execution on blockchain. In this paper, we present SLAB, a novel smart contract architecture that addresses these limitations by proposing parallel smart contract execution. We separate computation from consensus layer and leverage Intel SGX to scale transaction execution. SLAB uses three major concepts for optimization. First, we use smart locks and dependency tree to enable transaction execution in parallel. Second, by utilizing the trust properties of Trusted Execution Environments (TEEs), SLAB eliminates redundant transaction execution. Third, we support complex smart contract to smart contract calls by smart allocation of transactions and communication between compute nodes. We claim that our system is highly scalable. And, as compared to ethereum, we expect a many-fold increase in system throughput.

2021 · Data privacy is an important issue for businesses, governments, and the general public. Blockchain is an emerging technology that decentralizes trust among a number of potentially malicious peers in comparison to centralized systems. One of the challenges for blockchain systems is to provide privacy while providing high transaction throughput. Intel Software Guard Extensions (SGX), and other Trusted Execution Environments (TEEs) provide trust guarantees when executing a piece of code. Through this technology, several aspects of blockchains can be anonymized, thus preserving data privacy . In this paper, we present a systematic literature review of blockchain systems that use data privacy techniques with a focus on applications of Intel SGX.

2020 · One of the largest barriers to entry in machine learning is the scarcity of data. Several steps are involved in machine learning model creation, particularly, data collection, data preparation, choosing a model, training, etc. The project focuses on the step of data preparation, namely data augmentation, and specifically in the area of image processing. However, the framework proposed is extensible toward other data type, such as text, and video. Data augmentation is the creation of data from primary data samples using well-established transformations, such as rotations, pepper-salt distortions, etc. to create more samples for training a machine learning model. More notably, serverless computing, which involves a platform distributing processes across different transient servers, is increasingly a popular method in computing as it streamlines the setup of acquiring and establishing hardware, networks, etc. The project proposes framework that establishes a programming interface for serverless functions to be called to process the data.

2020 · T-Music is an innovative algorithm that composes a series of musical notes from a given series of input lyrics using frequent pattern mining as well as other data mining techniques. To demonstrate the capabilities of the algorithm, an online interface is desired for access to the public. The project identifies the user interactions required for T-Music and establishes a web interface for online access. The result of the project is an implementation of system design concepts to allow a maintainable and scalable system to deploy the usage of the algorithm.

2017 · Water is a very precious resource, it supports the lives of billions of people. However, due to a series of problems, water shortage becomes more prominent. [1]. This shortage causes not only economic slowdown, but also mortal illnesses and regional conflicts. Water shortage is occurring more frequently around the world in both developing and developed countries and arouses interest in its causes. This report will study water shortage in California. According to the California Department of Water Resources, the water demand in California mainly comprises of three domains in which 50% is for environmental use, 40% is for agricultural use, and 10% is for urban use [2]. For environmental use, the water is mainly for preservation of the ecology in some protected regions under the federal and states laws, and for maintaining the water quality for agricultural and urban uses [2]. Although environmental use is related to the hydrology in California, it indirectly affects human activities and significantly consume the water as compared to other uses – mainly agriculture. In the last few decades, due to the increasing yield of crops, and the switch to perennial crops [2], water usage dropped slightly for the industry. However, agricultural industry still relies on stable water supply heavily in order to produce good-quality, profitable crops. Being one of the major industries in California, which contributes to approximately 2% of the GDP of the state, together with other derived production profits [3], the water supply plays an important role in sustaining the economy of the industry and California. By comparing climate and agricultural data to the drought level in California as defined by the United States Drought Monitor (USDM), this report will provide an analysis of the causes of water shortage in California and compare and suggest solutions to mitigate the issue.
Dec 2nd, 2022
Nov 25th, 2022
Nov 18th, 2022
Nov 11th, 2022
Nov 4th, 2022
Oct 28th, 2022
Oct 21st, 2022
Oct 14th, 2022
Oct 7th, 2022
Oct 1st, 2022

For the team member voted as the most valuable player in the project.

For demonstrating outstanding leadership in the REDbird program.

For demonstrating outstanding performance in coaching and leadership.

For the group with the best poster design and presentation in a Hydrosystems Engineering course.

For the team that builds the best structure withstanding a series of earthquake testing.

Top 1% of graduates with a final CGA of at least 3.9.

For students that demonstrate: (a) excellent performance in academic studies; (b) recognized contribution to the institution/society; (c) demonstrated leadership and good communication skills; and (d) strong commitment to the Hong Kong community

For awarding outstanding first-year Engineering students choosing Civil & Environmental Engineering as their major program.

For the highest average upon graduating from a secondary school.

Numerous awards from high school.
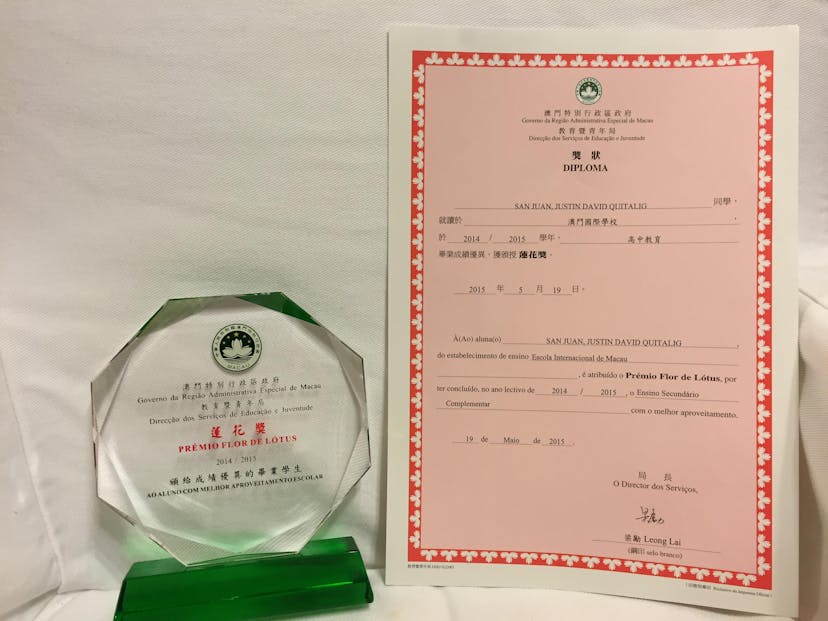
The highest average upon graduating from a secondary school.

For attaining the highest level of academic achievement of higher than 95%.

For one high school graduate for outstanding athletic achievement.

First place in the long-distance trail run in Repulse Bay.

Gold Awardee & Top Achiever. Chaired team of 8 to host 5 unique workshops to empower individuals. I also coached our junior cohort and guided them through their own discovery and leadership journey.

Organizing Committee Member. Orchestrated team of 18 to teach and support children in 3 different NGOs.

I love teaching and take the initiative to take instructional assistant roles in courses. Winter 2023 - [IA] CS116: Introduction to Computer Science 2 Fall 2022 - [IA] CS116: Introduction to Computer Science 2 Spring 2022 - [TA] CS251: Computer Organization and Design Winter 2022 - [IA] CS116: Introduction to Computer Science 2 Winter 2022 - [TA] CS116: Introduction to Computer Science 2 Fall 2021 - [TA] CS116: Introduction to Computer Science 2